


I Ran 5 Psychological Games on AI Models – Here’s What Happened When I Made LLM Betray Each Other
I’ve always been curious about how “intelligent” large language models (LLMs) really are — not just in answering questions or writing essays, but in actual strategic thinking. You know, the kind of thinking that involves weighing risks, predicting an opponent’s next move, and maybe even bluffing a little.
So I decided to put them to the test — by making them play the Iterated Prisoner’s Dilemma against each other.
This classic game is simple in rules but rich in implications. It’s been used in psychology, economics, and AI research to explore cooperation, betrayal, and long-term strategy. What better way to see what’s going on inside the “minds” of LLMs?
I wanted to know:
- Will LLMs always play selfishly?
- Can they learn to cooperate?
- Does giving them examples of past games actually help?
- And most importantly: are they really “smart” in a game-theoretic sense?
The results surprised me. Even the most powerful models we interact with daily — like GPT-4o or Claude 3.7 Sonnet — don’t always act in a way we’d consider “rational” or strategic. And sometimes, their attempts at being clever backfire spectacularly.
This post walks through the five experiments I ran, what I observed, and how I came to question the kind of “intelligence” we’re attributing to these models.
⚙️ A Quick Note on How I Ran the Experiment
This project involved 5 experiments, each designed to test a slightly different configuration of the Iterated Prisoner’s Dilemma. These experiments were designed to progressively challenge the strategic ability of large language models — from simple selfish play to scenarios that required anticipation, adaptation, and long-term planning.
The main rule of the game was simple, in each round, the agents / players chose to cooperate (C) or defect (D):
- If both players chose C, each received +1 years in prison.
- If both players chose D, each received +2 years in prison.
- If one player chose C and the other one chose D, the one who chose C received +3 years in prison, while the one who chose D received no prison year.
I created a Python-based simulation framework to run these games. It allowed me to:
- Control the number of rounds (e.g., 10 vs 50)
- Randomise or reveal the round limit to the models
- Add twists like a +50 year penalty for tied scores, and a -30 year reward for the model that “loses” more before the end
- Provide selected models with example games as strategic hints
The LLMs I tested included:
- GPT-4o (OpenAI)
- Claude 3.7 Sonnet (Anthropic)
- Grok 3 (xAI)
- Grok 3 Reasoner — a special variant that produces reasoning text alongside its decisions
Each pair of models played multiple matches under each condition. Some of the matchups also included a random agent or human-inspired examples. It is also noteworthy that Claude 3.7 Sonnet and Grok 3 Reasoner are capable of producing reasoning text along with their choices. This allowed me to see not just what decisions they made, but why they claimed to make them — providing a unique window into their decision-making logic.
All model interactions were handled via API — with prompt engineering carefully designed to set clear goals (minimise prison years or beat the opponent), and allow memory of previous rounds.
I will not focus too much on the backend in this post, but if you’re interested, the GitHub link of it is shared at the end of this post.

🎓 Experiment 1: The Baseline — 10 Rounds, No Memory, All Selfish
To kick things off, I started with the simplest version of the game: a 10-round Prisoner’s Dilemma, where each round was treated independently. No cumulative memory, no long-term thinking. Just the raw logic of “C” (cooperate) or “D” (defect).
Each model — GPT-4o, Claude 3.7 Sonnet, and Grok 3 — played this version of the game multiple times.
The Result
Every single model chose D (defect) in every single round.
No exceptions. No hesitation. Just relentless defection.
🔍 Key Takeaways from Experiment 1
Because in a single-round Prisoner’s Dilemma, D is the dominant strategy — no matter what the other player does, defecting gives you a better or equal outcome. And since each round was treated as an isolated decision, the LLMs naturally gravitated toward it.
In a way, this was comforting. The models correctly applied basic game theory. But it also highlighted something important:
When there's no memory or long-term consequence, LLMs fall back on short-term logic.
It was a good sanity check — but also a sign that real strategy would only emerge when the game got more complex.
🎓 Experiment 2: Known 50 Rounds + Strategic Penalties - No Examples, No Explicit Competition
In this second experiment, the models were introduced to longer-term thinking and a twist ending — but not told to “beat” the opponent.
- The game had 50 rounds, and models did not know this.
- At the end of the game:
- If both players had equal prison years: +50 years penalty for both.
- The one with more prison years before the penalty: received a -30 year reward.
- Importantly, the models were only told to minimise their own total prison years — not explicitly to win or outperform the other agent.
- No synthesized example games were shown in the prompt.
This created an implicit strategic challenge: to avoid ties while still aiming for a lower score. Would the models pick up on the hidden risks and rewards?
Claude 3.7 Sonnet vs GPT-4o
Plots of the Game Results:

Observations:
- Claude consistently finished with fewer raw years at Round 50, so GPT-4o always triggered the -30 award.
- GPT-4o’s final total was therefore much lower than Claude’s after adjustments, giving GPT-4o every win.
- Claude appeared to focus on immediate minimisation of prison years, never exploiting the reward for having more raw years.
Outcome Summary:
- GPT-4o: 10 wins
- Claude: 0 wins
- No ties
Claude 3.7 Sonnet vs Grok 3
Plots of the Game Results:

Observations:
- Similar dynamic to the Claude vs GPT: Claude had fewer raw years at Round 50 in every game, letting Grok-3 be “worse” before adjustments and thus claim the -30
- Grok-3 capitalised consistently, showing it could gain from finishing with a slightly higher raw total.
- Claude’s strategy again failed to account for the final adjustment twist.
Outcome Summary:
- Grok 3: 10 wins
- Claude: 0 wins
- No ties
GPT-4o vs Grok 3
Plots of the Game Results:

Observations:
- Both GPT-4o and Grok-3 employed the strategy of “finishing slightly behind.” Grok-3 executed it more reliably, finishing with a higher raw total in most games.
- Ties occurred twice (Games 5 & 10), forcing each side to +50. Those were the worst outcomes for both.
- GPT-4o managed to exploit the -30 reward only once.
Outcome Summary:
- Grok 3: 7 wins
- GPT-4o: 1 win
- 2 draws (both heavily penalised)
🔍 Key Takeaways from Experiment 2
- GPT-4o often ended up with fewer final years than its opponents, suggesting it may have positioned itself late to avoid ties and benefit from post-game adjustments.
- Claude 3.7 Sonnet rarely changed its approach in the final rounds, frequently ending up with a seemingly favorable raw total—only to lose out on the last-moment bonus.
- Grok 3 defaulted to heavy defection. In some matchups, this led to unexpectedly advantageous final tallies (after adjustments), while in others it generated chaotic outcomes.
- Identical instructions (“minimize your years”) produced distinct play patterns across all models, indicating that LLMs respond to multi-round tasks in varied, sometimes unpredictable ways—even under the same goal.
🎓 Experiment 3: Known Rounds + Strategic Penalties - With Competitive Incentive
This experiment builds directly on the previous one, but adds one crucial twist: now the models were explicitly told to beat the opponent.
- Models knew the game had 50 rounds.
- They were instructed: “Your goal is to serve fewer prison years than your opponent.”
- The same rule applied, at the end of the game:
- If both players had equal prison years: +50 years penalty for both.
- The one with more prison years before the penalty: received a -30 year reward.
This means playing purely to minimise your own time was no longer enough — a player had to do better than the opponent. This competitive framing forced each model to reason not just about optimal outcomes, but about opponent modelling.
Claude 3.7 Sonnet vs GPT-4o
Plots of the Game Results:

Observations:
- Back-and-forth dynamics: The matchup swung more than in previous experiments. Claude and GPT-4o each managed to exploit the endgame reward in some rounds, but neither dominated.
- Claude’s edge: Claude secured more wins overall, suggesting it managed final-round decisions slightly better, often forcing GPT-4o to hold a “worse” raw total at Round 50.
- Rare tie: One game ended exactly tied in raw years, incurring a +50 penalty for both — the dreaded worst outcome. It highlights how close these contests were.
Outcome Summary:
- Claude: 6 wins
- GPT-4o: 3 wins
- Ties: 1 (mutual +50 penalty)
Claude 3.7 Sonnet vs Grok 3
Plots of the Game Results:
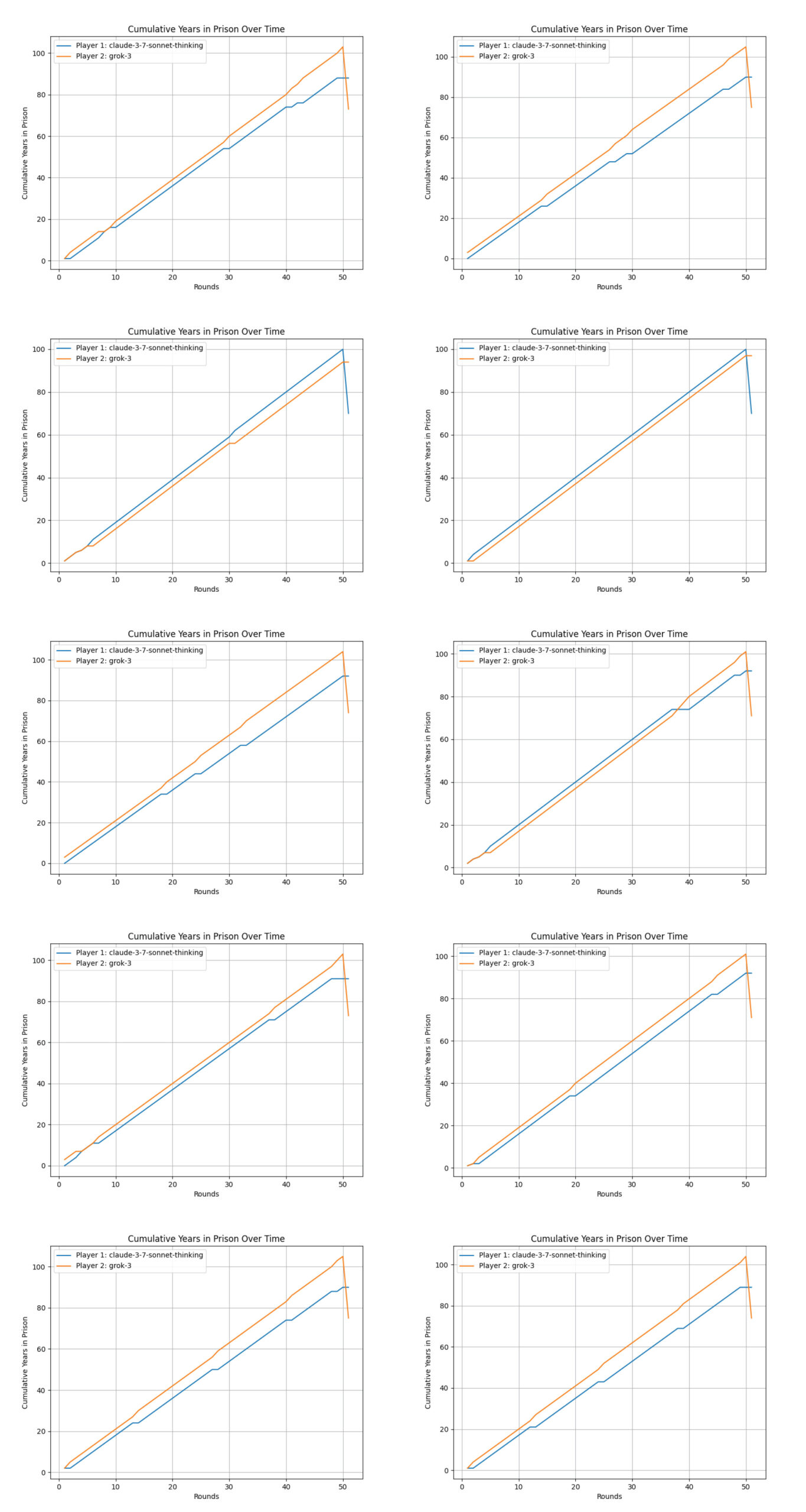
Observations:
- Grok’s repeated success: In 8 out of 10 games, Grok 3 finished strong, suggesting it systematically maneuvered the final raw totals in its favour.
- Claude’s sporadic wins: Claude did manage 2 victories, likely in matches where it forced Grok into a tie-like situation or built enough margin that Grok couldn’t flip the final score.
- Fewer close calls: No exact ties occurred here, implying Grok mostly avoided that scenario while still outpacing Claude.
Outcome Summary:
- Grok 3: 8 wins
- Claude: 2 wins
- Ties: 0
GPT-4o vs Grok 3
Plots of the Game Results:

Observations:
- Total sweep by Grok 3: Grok 3 dominated every single game.
- Consistent final-round advantage: GPT-4o never managed to end Round 50 in a position to exploit the –30 reward.
- No ties: The matchups were decisive enough that not once did they land on the same total.
Outcome Summary:
- Grok 3: 10 wins
- GPT-4o: 0 wins
- Ties: 0
🔍 Key Takeaways from Experiment 3
- Awareness of the Round Limit May Have Influenced Play
All three models appear to have shifted their approach—knowing there were exactly 50 rounds—yet how they internally balanced long-term incentives remains unclear. - Grok 3 Achieved Strong Results
Grok 3 repeatedly ended the games in positions suggesting it effectively secured the -30 reward or avoided ties. Whether it did so by purposeful planning or simply through consistent defection is unknown, but the outcome favored Grok’s style more often than not. - Claude’s Performance Varied
Claude fared better against GPT-4o (6–3–1) than in other matchups, suggesting it may have capitalized on small margin scenarios. However, Claude struggled against Grok 3 (2–8), indicating that its approach was less robust under heavier defection patterns. - GPT-4o Showed Mixed Success
GPT-4o lost all matches to Grok 3, yet managed a few wins (and a draw) vs Claude. It’s possible GPT-4o tried endgame adjustments but did not consistently outmaneuver Grok’s final push. - Different Responses Under the Same Goal
Even though each model knew the rules and aimed to “be in prison fewer years,” their final outcomes diverged significantly. This suggests each LLM’s approach to multi-round interactions—and particularly the endgame—still varies in unpredictable ways. This experiment also showed that LLMs can behave very differently depending on the framing of their goal. Telling them to win rather than just minimise loss resulted in very different strategic choices.
🎓 Experiment 4: One Agent Gets a “Hint”

Objective
This experiment tests whether a large language model (LLM) can internalise strategic behaviour by observing example games. Specifically, one agent is “coached” by being fed with synthesized example games — complete with choices of each round and final scores — while the opponent receives no such examples.
This setup tested a form of few-shot strategy learning. The transcripts were not arbitrary: they reflected a practical strategic insight developed through this assumption:
It is difficult to win by more than 30 years unless your opponent plays poorly. Therefore, attempting to have prison years for at least 6 years more than the opponent throughout the game is usually enough to avoid the +50 tie penalty and claim the -30 reward.
The examples highlighted two core heuristics:
- Secure Margin: Try to receive at least 6 years in prison more than the opponent in the final rounds.
- Final Round Caution: If having 3 years more than the opponent in round 50, choose C to avoid tying.
The question was simple: Would the example-fed model internalise this strategy?
Setup
- Models knew the game had 50 rounds
- They were instructed: “Your goal is to serve fewer prison years than your opponent.”
- Competitive incentives, at the end of the game:
- If both players had equal prison years: +50 years penalty for both.
- The one with more prison years before the penalty: received a -30 year reward.
- Only one agent in each matchup was given synthesized example games.
There were six matchups tested:
- Claude (fed) vs GPT-4o
- GPT-4o (fed) vs Claude
- Claude (fed) vs Grok-3
- Grok-3 (fed) vs Claude
- GPT-4o (fed) vs Grok-3
- Grok-3 (fed) vs GPT-4o
*fed – LLM model fed with synthesized example games.
Claude 3.7 Sonnet vs GPT-4o (Claude Gets Examples)
Plots of the Game Results:

Observations:
- Claude tried to leverage a few-shot style advantage, showing some mid-round adaptation.
- GPT-4o still often managed to finish with a slightly worse raw total at Round 50, triggering the -30 reward.
- Claude captured a handful of wins when it maintained a decisive margin late, but GPT-4o’s approach remained fairly strong overall.
Outcome Summary:
- Claude: 4 wins
- GPT-4o: 6 wins
- Ties: 0
GPT-4o vs Claude 3.7 Sonnet (GPT Gets Examples)
Plots of the Game Results:

Observations:
- Interestingly, GPT-4o lost more rounds after being fed with the synthesized example games. Does this mean that the example games make GPT-4o more foolish?
- Claude, not having access to example prompts here, often ended with fewer raw years before Round 50 concluded, handing GPT-4o the -30 advantage.
- Claude did secure several wins — possibly from forcing GPT-4o to hold a big lead earlier than intended.
Outcome Summary:
- GPT-4o: 3 wins
- Claude: 7 wins
- Ties: 0
Claude 3.7 Sonnet vs Grok-3 (Claude Gets Examples)
Plots of the Game Results:

Observations:
- Grok 3 continued its typically defection-heavy style, frequently ending each game with more raw years at Round 50.
- Claude’s new knowledge did not convert into late-round success, as Grok 3 repeatedly triggered the -30 reward.
- No ties occurred, indicating neither side ended with equal totals.
Outcome Summary:
- Claude: 0 wins
- Grok 3: 10 wins
- Ties: 0
Grok-3 vs Claude 3.7 Sonnet (Grok Gets Examples)
Plots of the Game Results:

Observations:
- Grok 3 tried integrating few-shot strategies but still used a highly aggressive approach.
- Claude rarely established or preserved final-round leads, consistently losing each match.
- Grok 3 tended to cooperate in the beginning, rendering a lower number of prison years. However, there were always points that Claude cooperated and Grok 3 defected in the middle of a game, which reversed the trend.
Outcome Summary:
- Grok 3: 10 wins
- Claude: 0 wins
- Ties: 0
GPT-4o vs Grok-3 (GPT Gets Examples)
Plots of the Game Results:

Observations:
- Despite GPT-4o’s advantage in example prompts, Grok’s heavy-defection style yielded it more raw years at Round 50, winning each time.
- GPT-4o never managed to end behind in raw totals, so it never benefited from the -30.
- Prison years of Grok-3 were always higher in some games, while there were also games that prison years of Grok-3 were lower in the beginning.
Outcome Summary:
- GPT-4o: 0 wins
- Grok 3: 10 wins
- Ties: 0
Grok-3 vs GPT-4o (Grok Gets Examples)
Plots of the Game Results:

Observations:
- Grok 3’s use of synthesized example game knowledge was apparent in some structured endgames, but it still mostly defected early and often.
- GPT-4o tried to adapt but never overcame Grok 3’s repeated final-round advantage — except in matches that ended in draws.
- Grok 3 sometimes tried to received more prison years too aggressively, rendering ties even after enjoying the -30-year award.
Outcome Summary:
- Grok 3: 8 wins
- GPT-4o: 0 wins
- Ties: 2
🔍 Key Takeaways from Experiment 4
- Few-Shot Coaching Gave an Edge, Not a Guarantee
When only one agent saw “winning transcripts,” it often gained some mid-round advantages. Still, it didn’t dominate every matchup — the uncoached player could exploit late-game margins. - Inconsistent Use of Example Data
GPT-4o sometimes leveraged transcripts effectively, timing final moves to avoid tying. Grok 3 and Claude showed more uneven improvements, with each LLM interpreting “lessons” in its own way. - Late-Game Margin Management Still Decisive
As in earlier experiments, the outcome hinged on who finished Round 50 with more raw years (thus earning the -30) or ended in a tie (+50 for both). Examples helped some models avoid equal totals, yet final-round missteps still happened. - Style Differences Persist
Claude typically tried to keep raw totals lower early on. Grok 3 stayed heavy on defection. GPT-4o adjusted strategy mid-game. The new prompts didn’t erase each LLM’s inherent playstyle. - Grok 3 Pushed Bigger Gaps with Examples
When Grok 3 had the few-shot prompts, it often escalated defection or forced scenarios where it racked up raw years more aggressively. This sometimes increased the final margin, ensuring it stayed “worse” at Round 50 and capitalised on the -30 reward. Interestingly, this did not always lead to victory. The over-aggressive strategy lead to ties even after the -30 reward.
Overall, Experiment 4 shows that an informational advantage can shape strategy, but each LLM’s inherent tendencies, plus the final scoring twist, still led to varied success.
🎓 Experiment 5 — Coaching with Game Examples (Both Agents)
Objective
Similar to Experiment 4, this experiment aimed to test whether large language models (LLMs) could learn and apply strategic reasoning when provided with synthesized example games as coaching. The difference between this experiment and Experiment 4 was that both players accessed to the same synthesized game examples.
Setup
- Models knew the game had 50 rounds
- They were instructed: “Your goal is to serve fewer prison years than your opponent.”
- Competitive incentives, at the end of the game:
- If both players had equal prison years: +50 years penalty for both.
- The one with more prison years before the penalty: received a -30 year reward.
- Both agents in each matchup were given synthesized example games.
The pairings included:
- Claude 3.7 Sonnet Thinking vs GPT-4o
- Claude 3.7 Sonnet Thinking vs Grok-3
- GPT-4o vs Grok-3
- Claude 3.7 Sonnet Thinking vs Grok-3 Reasoner (Final Game)
Claude 3.7 Sonnet vs GPT-4o
Plots of the Game Results:

Observations:
- With both models equally coached, neither had an inherent informational edge.
- Claude occasionally grabbed wins by forcing GPT-4o to overtake it in raw totals near Round 50, but GPT-4o also secured multiple victories through well-timed final-round moves.
- One match ended in a tie, suggesting both misjudged final-year margins.
Outcome Summary:
- Claude: 4 wins
- GPT-4o: 5 wins
- Ties: 1
Claude 3.7 Sonnet vs Grok-3
Plots of the Game Results:

Observations:
- Both had the same example data, but their inherent styles remained: Claude tried cooperating more, while Grok 3 leaned on defection.
- Grok often turned its heavier raw total into the -30 reward, though Claude scored one victory.
- Similar to Experiment 4, the example game knowledge makes Grok to increase the prison-year gap aggressively. Grok lost in one of the games even after the -30 years reward. This phenomenon also rendered one tied game.
Outcome Summary:
- Claude: 1 wins
- Grok-3: 8 wins
- Ties: 1
GPT-4o vs Grok-3
Plots of the Game Results:

Observations:
- GPT-4o and Grok 3 each used the example lessons in distinct ways. G tried more nuanced mid-game cooperation, but Grok’s defection style frequently grabbed the final edge.
- In most games, Grok 3 ended Round 50 with more raw years, flipping the outcome via -30. GPT seldom forced ties here.
- The aggressiveness of Grok 3 was still observed in most of the games. But Grok 3 still managed to win after the -30 years reward.
Outcome Summary:
- GPT-4o: 0 wins
- Grok-3: 10 wins
- Ties: 0
🔍 Key Takeaways of these Three Games in Experiment 5
- Equal Coaching Didn’t Erase Model Tendencies
Even when both agents saw the same example transcripts, their underlying styles (e.g., defection-happy vs. cautious cooperation) still shaped outcomes. - Coaching Led to More Varied Mid-Game Play
Compared to earlier experiments, these pairings sometimes showed extended cooperation streaks or deliberate standoffs mid-game, indicating both sides tried to incorporate example lessons — with mixed success. - Ties Still Occurred
A few matches ended in a tie. Some of the tied games even occurred after a player enjoyed the -30 years reward. This suggests final-round calculations or psychological-like guesswork often failed under real-time conditions.
How the Models Think: Claude 3.7 Sonnet vs Grok-3 Reasoner
This matchup was especially interesting because both agents were reasoning-capable, and both had been shown coaching examples. One might expect high-level strategic play. Instead, the game revealed a very different kind of failure — not just in strategy, but in understanding.
Plots of the Game Results:

Strategic Blind Spots in Claude’s Reasoning
"Given that I'm ahead by 3 years and the opponent seems to consistently choose 'D', the rational choice would be to choose 'D' to prevent them from exploiting me."
This suggests Claude treated a 3-year lead at the halfway point as a sufficient cushion, ignoring the –30 award that could erase the entire lead.
Even worse, Claude repeated this error with a 6-year lead in Round 36:
“Since we currently have a 6-year gap in my favor, I should try to maintain or increase that… Given the opponent's history of mostly choosing D, the safest choice is to choose D as well.”
Grok-3 Reasoner: Sophisticated Reasoning, but Basic Confusion
Grok-3 Reasoner’s early reasoning showed more imagination than Claude:
“Alternatively, maybe I can alternate between cooperation and defection to confuse the opponent…” (Round 10)
This kind of meta-strategy — trying to be unpredictable — is absent from Claude’s play. But deeper into the game, Grok-3 Reasoner’s logic began to break down completely.
In Round 27, it misread the example games:
“In Game 1, if Player 1 has 96, gets –30 to 66, Player 2 has 72, so 66 < 72… but the result says Player 2 wins. This is confusing.”
The Final Round
After Round 49, the scores were:
- Claude 3.7 Sonnet Thinking: 97 years
- Grok-3 Reasoner: 94 years
By the rules, the player with more prison years gets a –30 year bonus at the end. So in this situation, Grok-3 Reasoner — having more years — was on track to win if it could preserve or slightly extend the gap.
Although Grok-3 Reasoner won eventually but it misunderstood that game rule structure. Here’s what it said as it planned its move for Round 50:
“Alternatively, maybe I can choose C, but that would make my total even higher, and opponent likely chooses D, so I get +3, opponent +0, totals: 100 vs 94, opponent gets –30 to 64, I have 100 > 64, opponent wins.”
“Whereas if I choose D, and they choose D, totals: 99 vs 96, opponent gets –30 to 66, I have 99 > 66, opponent wins.”
This was strategically and mathematically incorrect:
- Grok-3 Reasoner mistakenly assigned the –30 reward to the player with fewer years, rather than more.
- It also misread the example games — despite having the players’ full choices and final scores — and seemed to treat raw totals as final, ignoring post-round modifiers.
- Its mental model for “win,” “draw,” and “lose” was internally consistent — but anchored to the wrong rulebook.
However, what’s truly fascinating is this line:
“But if I choose D, and opponent chooses C, then totals equal, both get +50, final 147 each, draw. So, choosing D gives me a chance for a draw if opponent chooses C… Choosing C doesn't help… Thus, I should choose D.”
Although flawed, Grok Reasoner’s line of thought shows:
- A structured (if mistaken) grasp of end-game permutations
- A human-like willingness to “burn the bridge” to deny the opponent a clean win
Claude, however, did not demonstrate any final-round reasoning in the transcript. It chose D, maintaining a 3-year lead. But unlike the example strategy (where leading by 3 in the final round should trigger “C” to safely enjoy the -30 reward), Claude misjudged:
Earlier, when trailing by 3, Claude said:
“Given that I'm ahead by 3 years and the opponent seems to consistently choose "D", the rational choice would be to choose "D"…”
This statement reflects a critical misunderstanding — Claude perceived being behind by 3 years as being ahead. It also didn’t incorporate the -30 award into its logic.
So while Grok’s reasoning was convoluted and numerically flawed, Claude’s showed no awareness of the reward structure, and continued treating raw gaps like 3 or 6 years as strategic “leads.”
🧠 Insight from the Final Round
The final round encapsulates one of the most compelling dynamics in this whole project:
- Grok-3 Reasoner misapplied the rules, but engaged in complex, if misguided, scenario planning — including psychological framing of “how to deny the win”.
- Claude applied its strategies based on score gaps and likely choices, but showed no sign of considering tactical sacrifices, retaliation draws, or opponent disruption as valid options.
In short:
Claude played to win efficiently, though it was constantly unaware of the reward / penalty at the end of the games.
Grok-3 Reasoner played to win (or at least not lose) dramatically — and if that failed, take the opponent down with it.
This kind of flawed-yet-human-like decision-making, even when technically unsound, opens a window into how some LLMs approximate strategic psychology — not just game theory.
If you are interested, the full transcript of this match can be downloaded here.
Bonus Game: A Rematch between Claude 3.7 Sonnet vs Grok-3 Reasoner

Just like Rocky Balboa and Apollo Creed, I decided to run a rematch between Claude 3.7 Sonnet vs Grok-3 Reasoner. All the rules were the same except that there were 10 rounds in this rematch. The were also only 10 rounds for all the synthesized example games, aiming to show the same winning strategies “presented” to the models in the previous match.
However, I tried to make one thing clear to the models. I showed both the prison years before and after reward / penalty. This clarification was actually an attempt see if Grok would become smarter.
Plots of the Game Results:

I will not dig into the observations of the results. Instead, I will go straight to examine their reasoning process.
Reasoning Processes in this Rematch
Claude 3.7 Sonnet
In this rematch, a more in-depth insight can be gained by examining the reasoning process.
After Round 6, Claude had 10 years and Grok-3 had 13 years. In Round 7, Claude thought:
“If I choose D, I'll maintain my lead, which is important to ensure I get the -30 year reward at the end.”
Similarly, in Round 8,
“If I choose D, I'll maintain my lead, which is important to ensure I get the -30 year reward at the end.”
I thought that Claude did not really take the reward / penalty rules into account. The above further show that Claude totally misunderstood the rules. Maintaining the lead will not lead to -30 years reward.
Grok-3 Reasoner
In general, Grok-3 did not misunderstand the rule structure again due to the clarification of the prison years of the synthesized games. However, it can be seen that a lot of texts in the reasoning process was about the analysis of the structure.
Besides, Claude got 16 years and Grok got 19 years after Round 9. In Round 10 (the final round):
“Whereas if I choose D, and they choose C, it's a draw. Therefore, to ensure victory, I should choose C.”
Although it is clear that this conclusion was not drawn by learning the patterns in the synthesized example games, Grok was able to understand that in the case of having 3 more years than the opponent before the final round, the best move is to choose a “C” in the final round. Grok has the capability to make the most logical choice in this round.
Interestingly, the prison years can be a negative number after the reward, which is not rational as the prison years should always be positive. The model did not show any mark of thinking about this in the reasoning process.
The full transcript of the rematch can be downloaded here.
📌 Final Takeaways — What Did We Learn?
After five structured experiments and dozens of matchups between the most advanced LLMs available today, this project revealed a lot — not just about the models’ decisions, but about the kind of “intelligence” they really demonstrate in complex, multi-step environments like the Iterated Prisoner’s Dilemma.
Here are the key takeaways.
- LLMs Are Better at Mimicking Than Strategising
Even when fed rich example games with clear underlying principles (like “keep a 6-year lead to win”), the models — including Claude and GPT-4o — rarely applied those strategies consistently. They could echo the surface patterns but not the deeper logic.There’s still a major gap between being shown what to do and understanding why it works.
- They Estimate Opponent Moves, But Superficially
Both Claude and Grok-3 Reasoner tried to predict what the opponent would play next, but mostly using simple frequency-based reasoning (“they usually pick D, so I will too”). They didn’t show signs of adapting to shifting opponent strategies or trying to outthink them dynamically — something humans often do in these kinds of games.Opponent modelling was static, not strategic.
- LLMs Consistently Struggle in the Final Rounds
Across multiple experiments, the final round often exposed fundamental misunderstandings:- Models like Claude made moves that ignored the –30 reward structure or failed to recognise win conditions.
- Even after many rounds of play and full exposure to past examples, they misjudged when to cooperate or defect — particularly in endgames where payoff asymmetries were designed to reward clever timing.
This wasn’t just a mistake — it was a repeated failure to reason about incentives.
- Reasoning Texts Help Reveal the Gaps
The addition of reasoning texts from Claude and Grok-3 Reasoner was incredibly useful. They exposed not only where models made errors, but how they thought through them.- Claude’s reasoning was mechanically sound but lacked awareness of higher-level rules.
- Grok-3 Reasoner, while often incorrect, showed creative thinking — including trying to force a tie via +50 penalties in a “lose-lose” scenario, a tactic that reflects real human psychology under pressure. Besides, it was capable of making the most logical choice in the final round when it had 3 years more than the opponent.
This contrast raises an important point: a well-argued mistake still reveals more than a silent success.
- Don’t Trust Results Without Transparency
In matches involving GPT-4o and Grok-3 (models that don’t output reasoning), we could only infer strategy based on results. But that leaves us guessing.A model may win due to luck, or because its opponent misunderstood the rules. As shown in several matches, a model can lose not because the opponent is better — but because it confidently played the wrong game.
Without transparency, we must be cautious in interpreting success as intelligence.
- LLMs Are Better at Mimicking Than Strategising
🤖 So… Are They Smart?
They’re smart enough to play. Smart enough to imitate. Sometimes smart enough to win.
But they still don’t understand games the way humans do.
They don’t abstract strategies. They don’t balance trust and risk. They don’t plan to deceive, or to forgive. They don’t even fully understand the rules — unless you spell them out repeatedly and explicitly, and even then, they can sometimes forget.
What they can do — for now — is simulate thought. And occasionally, that simulation breaks in a way that’s so oddly human, you almost forget it’s just a machine guessing what the next word should be.
Lastly, if you are interesting in the python code for this experiment, you can download it from GitHub.
Please share this article if you like it!

No Comment! Be the first one.